이 글은 FastCampus에서 진행하는 "백엔드 개발자를 위한 한 번에 끝내는 대용량 데이터 & 트래픽 처리 초격차 패키지 Online" 강의를 공부하고 기록하기 위함입니다. 저작권 등이 문제가 생긴다면 바로 정리하도록 하겠습니다.
수 많은 Database 중 MySQL을 선택한 이유에 대해서 먼저 소개해볼게요.

전세계에서 가장 많이 사용되고 있는 DB 20위 중 13개가 관계형 Database로 나오고 있어요. 그 중 TOP4는 모두 관계형 DB인 만큼 아직 시장에서 관계형 DB에 대한 활용성이 많은 것 같습니다. 기업에서도 많이 활용하고 있기 때문에 백엔드 개발자라면 관계형 DB에 대한 경험이 실무에서 많이 중요하 것 같아요
물론 관계형 DB 중에서도 MySQL 외 다른 DB에 대해서도 공부하는 시간은 필요합니다. 각 DB마다 장단점이 있고 개발하는 서비스와 목적에 따라 사용하게 될 수도 있으니까요. 그래도 하나의 DB를 깊이있게 공부하다 보면 다른 종류의 DB를 새로 접할때도 생각보다 쉽게 학습하실 수 있어요. 관계형 DB 외에도 여러 DB에 대한 공부도 물론 필요하구요
MySQL은 많이 쓰나요?
MySQL을 가장 인기 많은 오픈소스 관계형 DB에요. 오픈소스니 당연히 내부 로직이 어떻게 실행되는지도 볼 수 있죠
GitHub - mysql/mysql-server: MySQL Server, the world's most popular open source database, and MySQL Cluster, a real-time, open s
MySQL Server, the world's most popular open source database, and MySQL Cluster, a real-time, open source transactional database. - GitHub - mysql/mysql-server: MySQL Server, the world's mos...
github.com
전세계에서 가장 사랑받는 만큼 코드의 양도 많기 때문에 모든 코드를 하나씩 보기가 쉽지는 않아요. 그래서 필요할 땐 아래 가이드를 참조하실 수도 있습니다.
MySQL: Welcome
Welcome to the MySQL source code documentation.This documentation covers primarily the MySQL server, for the mysqld process. Other programs, like the MySQL Router, are also documented, see the Server tools section. The order chosen to present the content i
dev.mysql.com
네이버, 카카오, 토스 등 국내 최고의 IT기업 뿐만 아니라 미국 BigTech 기업인 Netfilx, Twitter, Amazon, Airbnb등 많은 회사도 MySQL을 사용하고 있네요
MySQL 아키텍처 소개
그럼 MySQL은 어떠한 구조로 되어 있는지 간단히 알아보겠습니다.
데이터베이스는 파일을 관리하는 서버에요. 데이터베이스 입장에선 서버가 Client가 될 수도 있죠.
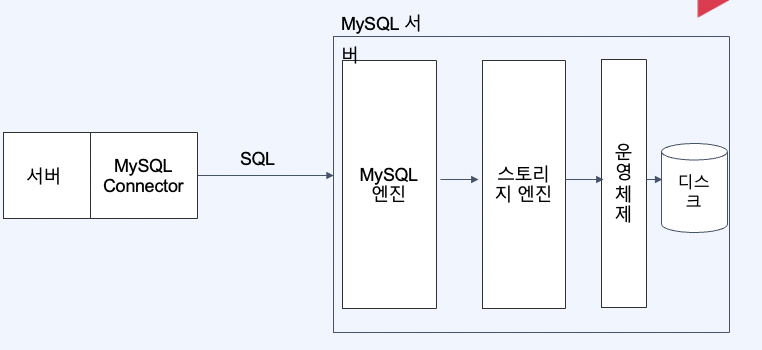
서버가 데이터베이스로 요청을 하면 MySQL 내부에선 MySQL 엔진 -> 스토리지 엔진 -> 운영체제 -> 디스크로 접근하여 데이터를 서버에게 최종적으로 전달하게 됩니다. 이번 포스팅에선 MySQL 엔진에 대해 자세히 한번 알아볼게요
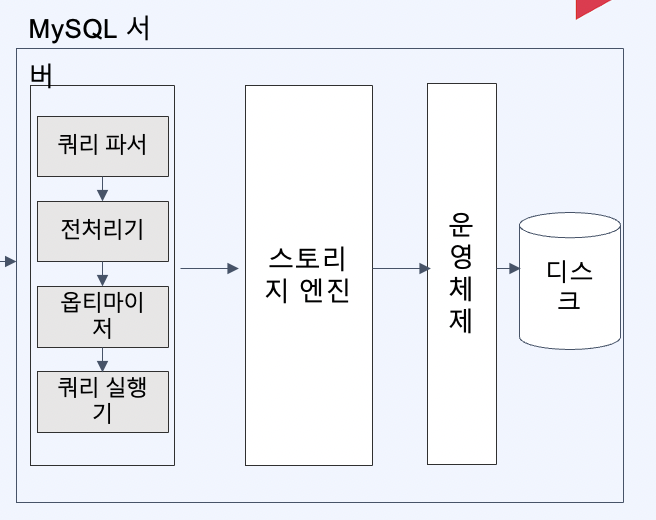
MySQL엔진은 쿼리 파서, 전처리기, 옵티마이저 , 쿼리 실행기로 구성되어 있어요
쿼리파서
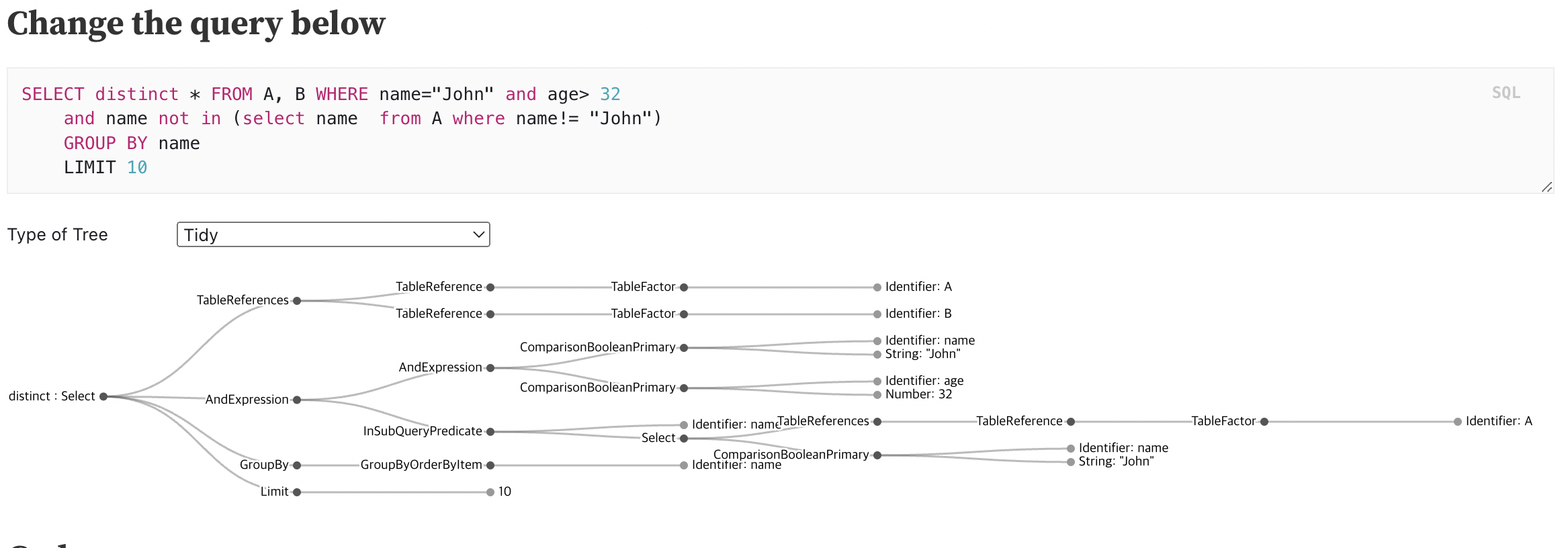
SQL을 파싱하여 Syntax Tree를 만들어요. 이 과정에서 문법에 오류가 있는지 검사를 진행하게 됩니다.
SQL Query Visualizer라는 서비스에서 Query를 입력하면 이를 어떻게 Syntax Tree로 변환되는지 확인할 수 있어요
전처리기
쿼리파서에서 만든 Syntax Tree를 바탕으로 전처리를 시작해요. 어떤 전처리를 할까요? Syntax tree에 있는 테이블이나 View, Column이 존재하는지, 그리고 해당 데이터에 접근 권한이 있는지 Semantic 오류 검사를 진행해요.
여기서 Semantic 오류검사란 문법적으로는 문제가 없으나 논리적인 오류를 말해요. 예를들어 문법은 괜찮으나 해당 테이블,컬럼이 존재하지 않거나? 권한이 없다거나? 아니면 자판기에 1000원을 넣고 500원짜리 음료수를 마시면 거스름돈으로 500원을 줘야하는데 다시 1000원을 주거나 하는 논리적인 오류를 의미해요
쿼리파서, 전처리기는 컴파일 과정과 유사해요. 본격적인 데이터를 가져오기 전 문법적인 논리적인 오류가 있는지 검사하는거죠
옵티마이저
옵티마이저는 Query를 처리하기 위한 여러 방법을 만들고, 각 방법들의 비용정보와 테이블의 통계정보를 이용해서 전체적인 비용을 산정하는 역할을 해요. 테이블 순서, 불필요한 조건 제거, 통계정보를 바탕으로 어떤 전략으로 데이터를 가져올지 결정하죠. 이를 실행계획 수립이라고 해요
옵티마이저가 어떤 전략을 결정하느냐에 따라 성능이 많이 차이나게 됩니다. 옵티마이저가 이러한 전략을 항상 옳게 선택하지 못할 수 있기 대문에 저희같은 백엔드 개발자가 힌트를 사용해서 좋은 전략을 수립하도록 도와줄 수 있어요
쿼리실행기
이렇게 옵티마이저가 실행계획을 수립하면, 쿼리 실행기는 이것을 기반으로 스토리지 엔진에 요청을 하게 됩니다. 이때 Handler API를 사용하게 되는데 MySQL을 사용하시다면 Handler이란 용어를 자주 보시게 될거에요. 스토리지 엔진에 직접 요청하는 것을 Handler 요청이라고 하고 이를 API를 직접 구현해서 사용할 수도 있어요
그럼 MySQL 엔진의 4가지 작업 중 어떤 부분에서 가장 많은 시간이 소요되고 비용이 높을까요?
바로 옵티마이저입니다. 실행 계획이 Query 성능에 아주 큰 영향을 주기 때문에 옵티마이저의 역할이 중요하고 그 만큼 소요시간도 많이 걸리게 됩니다.
그럼 같은 Query 요청이 올 경우를 대비하여 실행계획을 캐싱에 저장해두면 어떻게 될까요? 그러면 옵티마이저를 거치지 않고 마로 쿼리실행기에 도달할 수 있어 성능이 많이 좋아질 것 같은 생각이 드네요.
이를 쿼리 캐싱이라하는데, 아쉽게도 MySQL 5.0까지는 이 기능이 존재했습니다. 8.0 버전 이후부터는 이를 사용할 수 없는대요. 과연 왜그럴까요?
캐싱에서 사용할 수 있는 파싱 방법에는 소프트, 하드 두가지 방식이 있어요
소프트 파싱 : SQL, 실행계획을 캐시에서 찾아 옵티파이저 과정을 생략하고 발 실행단계로 넘어감
하드 파싱 : SQL, 실행계획을 캐시에서 찾지못해 옵티마이저 과정을 거쳐 실행단계로 넘어감
MySQL에는 이제 소프트 파싱은 지원하지 않는거죠. 실행계획이나 데이터를 캐싱에 저장해둔다면 이를 조회할 때는 성능상으로 많은 이점이 있을 수 있어요. 그러나 데이터가 변경된 경우는 어떨까요? 데이터가 변경될 때는 캐싱되어 있는 데이터 및 실행계획을 갱신해야 합니다. 갱신을 할때도 역시 비용과 시간이 소요됩니다. MySQL 측에서는 캐싱을 함으로서 얻을 수 있는 이점보다 갱신하는데 필요한 비용,시간이 더 크다고 판단해서 그런건 아닐까요?
이와 반대로 Oracle에서는 소프트 파싱이 존재하고 실행계획까지만 캐싱해놓고 있어요. 물론 HINT설정을 통해 데이터까지 캐싱하는것도 가능합니다.
이렇게 어떤 데이터를 사용하고 조회가 많은지, 삽입이 많은지에 따라 소프트 파싱 기능이 필요할 수도 필요하지 않을 수도 있을것 같아요. 만약 데이터가 새로 추가되거나 변경되는 빈도가 적고 조회가 월등히 많은 서비스라면 소프트 파싱을 지원하는 Oracle을 채택하는게 좋은 선택일 수도 있겠죠?
결국 모든 기술을 트레이드 오프인 것 같아요
다음 포스팅부터는 회원정보부터 차근차근 개발해나가도록 하겠습니다.이번 글도 읽어주셔서 감사합니다!
'Computer Science > 서버 개발' 카테고리의 다른 글
| [대용량 처리를 위한 MySQL 이해] SNS 서비스 만들기 - 회원정보 등록 구현 (0) | 2023.05.01 |
|---|---|
| [대용량 처리를 위한 MySQL 이해] 대용량 시스템의 이해 (2) | 2023.04.29 |
| [대용량 처리를 위한 MySQL 이해] SNS 서비스 만들기 - 실습환경 구축 (0) | 2023.04.29 |
| [대용량 처리를 위한 MySQL 이해] 대용량 서버를 구축하기 위해서는 어떤걸 알아야 할까? (0) | 2023.04.29 |


